

 Abstract.
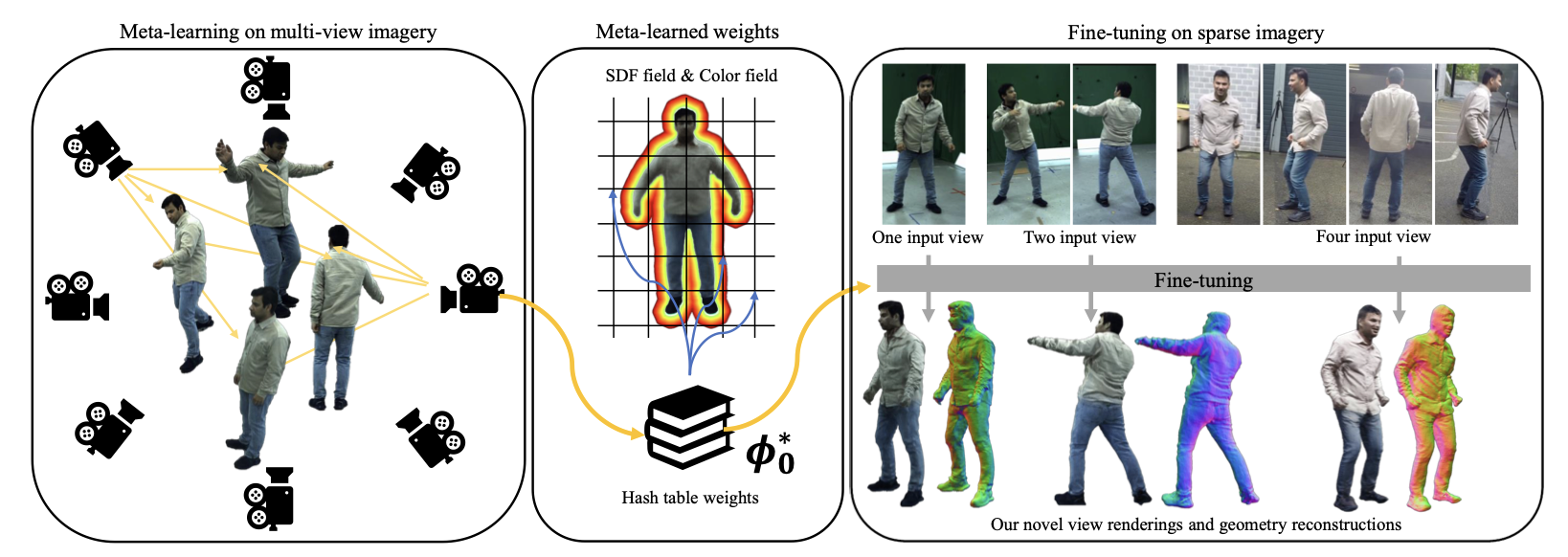
Faithful human performance capture and free-view render- ing from sparse RGB observations is a long-standing problem in Vision and Graphics. The main challenges are the lack of observations and the inherent ambiguities of the setting, e.g. occlusions and depth ambiguity. As a result, radiance fields, which have shown great promise in capturing high-frequency appearance and geometry details in dense setups, perform poorly when naïvely supervising them on sparse camera views, as the field simply overfits to the sparse-view inputs. To address this, we propose MetaCap, a method for efficient and high-quality geometry recovery and novel view synthesis given very sparse or even a single view of the human. Our key idea is to meta-learn the radiance field weights solely from potentially sparse multi-view videos, which can serve as a prior when fine-tuning them on sparse imagery depicting the human. This prior provides a good network weight initialization, thereby effectively addressing ambiguities in sparse-view capture. Due to the articulated structure of the human body and motion-induced surface deformations, learning such a prior is non-trivial. Therefore, we propose to meta-learn the field weights in a pose-canonicalized space, which reduces the spatial feature range and makes feature learning more effective. Consequently, one can fine-tune our field parameters to quickly generalize to unseen poses, novel illumination conditions as well as novel and sparse (even monocular) camera views. For evaluating our method under different scenarios, we collect a new dataset, WildDynaCap, which contains subjects captured in, both, a dense camera dome and in-the-wild sparse camera rigs, and demonstrate superior results compared to recent state-of-the-art methods on both public and WildDynaCap dataset.
Abstract.
Faithful human performance capture and free-view render- ing from sparse RGB observations is a long-standing problem in Vision and Graphics. The main challenges are the lack of observations and the inherent ambiguities of the setting, e.g. occlusions and depth ambiguity. As a result, radiance fields, which have shown great promise in capturing high-frequency appearance and geometry details in dense setups, perform poorly when naïvely supervising them on sparse camera views, as the field simply overfits to the sparse-view inputs. To address this, we propose MetaCap, a method for efficient and high-quality geometry recovery and novel view synthesis given very sparse or even a single view of the human. Our key idea is to meta-learn the radiance field weights solely from potentially sparse multi-view videos, which can serve as a prior when fine-tuning them on sparse imagery depicting the human. This prior provides a good network weight initialization, thereby effectively addressing ambiguities in sparse-view capture. Due to the articulated structure of the human body and motion-induced surface deformations, learning such a prior is non-trivial. Therefore, we propose to meta-learn the field weights in a pose-canonicalized space, which reduces the spatial feature range and makes feature learning more effective. Consequently, one can fine-tune our field parameters to quickly generalize to unseen poses, novel illumination conditions as well as novel and sparse (even monocular) camera views. For evaluating our method under different scenarios, we collect a new dataset, WildDynaCap, which contains subjects captured in, both, a dense camera dome and in-the-wild sparse camera rigs, and demonstrate superior results compared to recent state-of-the-art methods on both public and WildDynaCap dataset.
 Abstract.
Creating a controllable and relightable digital avatar from multi-view video with fixed illumination is a very challenging problem since humans are highly articulated, creating pose-dependent appearance effects, and skin as well as clothing require space-varying BRDF modeling. Existing works on creating animatible avatars either to not focus on relighting at all, require controlled illumination setups, or try to recover a relightable avatar from very low cost setups, i.e. a single RGB video, at the cost of severely limited result quality, e.g. shadows not even being modeled. To address this, we propose Relightable Neural Actor, a new video-based method for learning a pose-driven neural human model that can be relighted, allows appearance editing, and models pose-dependent effects such as wrinkles and self-shadows. Importantly, for training, our method solely requires a multi-view recording of the human under a known, but static lighting condition. To tackle this challenging problem, we leverage an implicit geometry representation of the actor with a drivable density field that models pose-dependent deformations and derive a dynamic mapping between 3D and UV spaces, where normal, visibility, and materials are effectively encoded. To evaluate our approach in real-world scenarios, we collect a new dataset with four identities recorded under different light conditions, indoors and outdoors, providing the first benchmark of its kind for human relighting, and demonstrating state-of-the-art relighting results for novel human poses.
Abstract.
Creating a controllable and relightable digital avatar from multi-view video with fixed illumination is a very challenging problem since humans are highly articulated, creating pose-dependent appearance effects, and skin as well as clothing require space-varying BRDF modeling. Existing works on creating animatible avatars either to not focus on relighting at all, require controlled illumination setups, or try to recover a relightable avatar from very low cost setups, i.e. a single RGB video, at the cost of severely limited result quality, e.g. shadows not even being modeled. To address this, we propose Relightable Neural Actor, a new video-based method for learning a pose-driven neural human model that can be relighted, allows appearance editing, and models pose-dependent effects such as wrinkles and self-shadows. Importantly, for training, our method solely requires a multi-view recording of the human under a known, but static lighting condition. To tackle this challenging problem, we leverage an implicit geometry representation of the actor with a drivable density field that models pose-dependent deformations and derive a dynamic mapping between 3D and UV spaces, where normal, visibility, and materials are effectively encoded. To evaluate our approach in real-world scenarios, we collect a new dataset with four identities recorded under different light conditions, indoors and outdoors, providing the first benchmark of its kind for human relighting, and demonstrating state-of-the-art relighting results for novel human poses.
 Abstract.
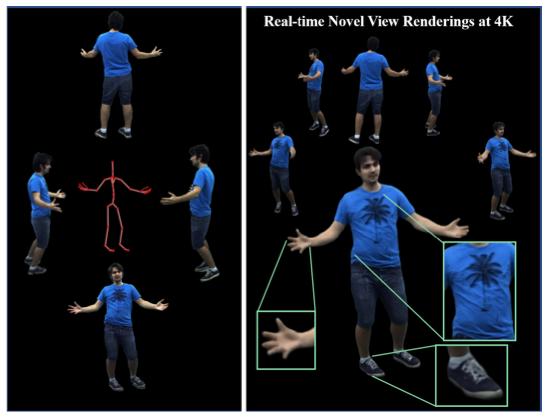
We present the first approach to render highly realistic free-viewpoint videos of a human actor in general apparel, from sparse multi-view recording to display, in real-time at an unprecedented 4K resolution. At inference, our method only requires four camera views of the moving actor and the respective 3D skeletal pose. It handles actors in wide clothing, and reproduces even fine-scale dynamic detail, e.g. clothing wrinkles, face expressions, and hand gestures. At training time, our learning-based approach expects dense multi-view video and a rigged static surface scan of the actor. Our method comprises three main stages. Stage 1 is a skeleton-driven neural approach for high-quality capture of the detailed dynamic mesh geometry. Stage 2 is a novel solution to create a view-dependent texture using four test-time camera views as input. Finally, stage 3 comprises a new image-based refinement network rendering the final 4K image given the output from the previous stages. Our approach establishes a new benchmark for real-time rendering resolution and quality using sparse input camera views, unlocking possibilities for immersive telepresence.
Abstract.
We present the first approach to render highly realistic free-viewpoint videos of a human actor in general apparel, from sparse multi-view recording to display, in real-time at an unprecedented 4K resolution. At inference, our method only requires four camera views of the moving actor and the respective 3D skeletal pose. It handles actors in wide clothing, and reproduces even fine-scale dynamic detail, e.g. clothing wrinkles, face expressions, and hand gestures. At training time, our learning-based approach expects dense multi-view video and a rigged static surface scan of the actor. Our method comprises three main stages. Stage 1 is a skeleton-driven neural approach for high-quality capture of the detailed dynamic mesh geometry. Stage 2 is a novel solution to create a view-dependent texture using four test-time camera views as input. Finally, stage 3 comprises a new image-based refinement network rendering the final 4K image given the output from the previous stages. Our approach establishes a new benchmark for real-time rendering resolution and quality using sparse input camera views, unlocking possibilities for immersive telepresence.
 Abstract.
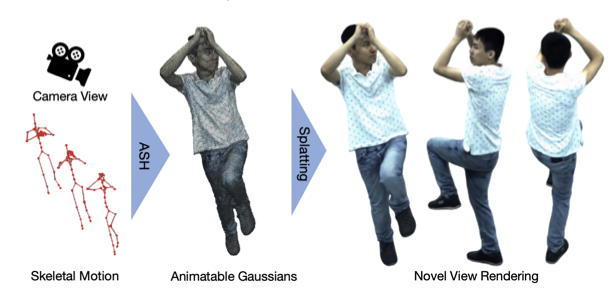
Real-time rendering of photorealistic and controllable human avatars stands as a cornerstone in Computer Vision and Graphics. While recent advances in neural implicit rendering have unlocked unprecedented photorealism for digital avatars, real-time performance has mostly been demonstrated for static scenes only. To address this, we propose ASH, an Animatable Gaussian Splatting approach for photorealistic rendering of dynamic Humans in real time. We parameterize the clothed human as animatable 3D Gaussians, which can be efficiently splatted into image space to generate the final rendering. However, naively learning the Gaussian parameters in 3D space poses a severe challenge in terms of compute. Instead, we attach the Gaussians onto a deformable character model, and learn their parameters in 2D texture space, which allows leveraging efficient 2D convolutional architectures that easily scale with the required number of Gaussians. We benchmark ASH with competing methods on pose-controllable avatars, demonstrating that our method outperforms existing real-time methods by a large margin and shows comparable or even better results than offline methods.
Abstract.
Real-time rendering of photorealistic and controllable human avatars stands as a cornerstone in Computer Vision and Graphics. While recent advances in neural implicit rendering have unlocked unprecedented photorealism for digital avatars, real-time performance has mostly been demonstrated for static scenes only. To address this, we propose ASH, an Animatable Gaussian Splatting approach for photorealistic rendering of dynamic Humans in real time. We parameterize the clothed human as animatable 3D Gaussians, which can be efficiently splatted into image space to generate the final rendering. However, naively learning the Gaussian parameters in 3D space poses a severe challenge in terms of compute. Instead, we attach the Gaussians onto a deformable character model, and learn their parameters in 2D texture space, which allows leveraging efficient 2D convolutional architectures that easily scale with the required number of Gaussians. We benchmark ASH with competing methods on pose-controllable avatars, demonstrating that our method outperforms existing real-time methods by a large margin and shows comparable or even better results than offline methods.
 Abstract.
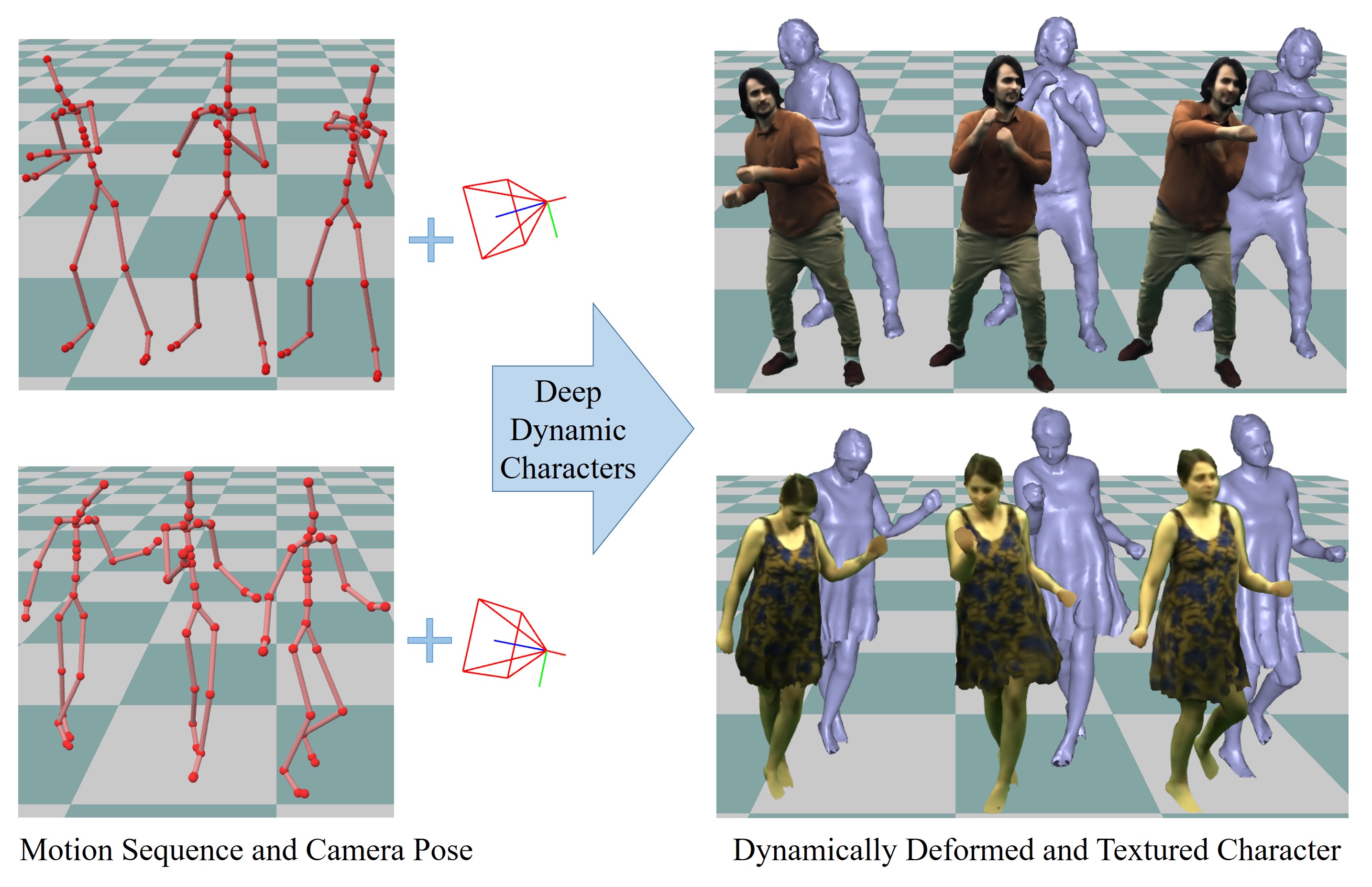
We propose a deep videorealistic 3D human character model displaying highly realistic shape, motion, and dynamic appearance learned in a new weakly supervised way from multi-view imagery. In contrast to previous work, our controllable 3D character displays dynamics, e.g., the swing of the skirt, dependent on skeletal body motion in an efficient data-driven way, without requiring complex physics simulation. Our character model also features a learned dynamic texture model that accounts for photo-realistic motion-dependent appearance details, as well as view-dependent lighting effects. During training, we do not need to resort to difficult dynamic 3D capture of the human; instead we can train our model entirely from multi-view video in a weakly supervised manner. To this end, we propose a parametric and differentiable character representation which allows us to model coarse and fine dynamic deformations, e.g., garment wrinkles, as explicit space-time coherent mesh geometry that is augmented with high-quality dynamic textures dependent on motion and view point. As input to the model, only an arbitrary 3D skeleton motion is required, making it directly compatible with the established 3D animation pipeline. We use a novel graph convolutional network architecture to enable motion-dependent deformation learning of body and clothing, including dynamics, and a neural generative dynamic texture model creates corresponding dynamic texture maps. We show that by merely providing new skeletal motions, our model creates motion-dependent surface deformations, physically plausible dynamic clothing deformations, as well as video-realistic surface textures at a much higher level of detail than previous state of the art approaches, and even in real-time.
Abstract.
We propose a deep videorealistic 3D human character model displaying highly realistic shape, motion, and dynamic appearance learned in a new weakly supervised way from multi-view imagery. In contrast to previous work, our controllable 3D character displays dynamics, e.g., the swing of the skirt, dependent on skeletal body motion in an efficient data-driven way, without requiring complex physics simulation. Our character model also features a learned dynamic texture model that accounts for photo-realistic motion-dependent appearance details, as well as view-dependent lighting effects. During training, we do not need to resort to difficult dynamic 3D capture of the human; instead we can train our model entirely from multi-view video in a weakly supervised manner. To this end, we propose a parametric and differentiable character representation which allows us to model coarse and fine dynamic deformations, e.g., garment wrinkles, as explicit space-time coherent mesh geometry that is augmented with high-quality dynamic textures dependent on motion and view point. As input to the model, only an arbitrary 3D skeleton motion is required, making it directly compatible with the established 3D animation pipeline. We use a novel graph convolutional network architecture to enable motion-dependent deformation learning of body and clothing, including dynamics, and a neural generative dynamic texture model creates corresponding dynamic texture maps. We show that by merely providing new skeletal motions, our model creates motion-dependent surface deformations, physically plausible dynamic clothing deformations, as well as video-realistic surface textures at a much higher level of detail than previous state of the art approaches, and even in real-time.
Dataset Details
 Human performance capture is a highly important computer vision problem with many applications in movie production and virtual/augmented reality. Many previous performance capture approaches either required expensive multi-view setups or did not recover dense space-time coherent geometry with frame-to-frame correspondences. We propose a novel deep learning approach for monocular dense human performance capture. Our method is trained in a weakly supervised manner based on multi-view supervision completely removing the need for training data with 3D ground truth annotations. The network architecture is based on two separate networks that disentangle the task into a pose estimation and a non-rigid surface deformation step. Extensive qualitative and quantitative evaluations show that our approach outperforms the state of the art in terms of quality and robustness. This work is an extended version of DeepCap where we provide more detailed explanations, comparisons and results as well as applications.
Human performance capture is a highly important computer vision problem with many applications in movie production and virtual/augmented reality. Many previous performance capture approaches either required expensive multi-view setups or did not recover dense space-time coherent geometry with frame-to-frame correspondences. We propose a novel deep learning approach for monocular dense human performance capture. Our method is trained in a weakly supervised manner based on multi-view supervision completely removing the need for training data with 3D ground truth annotations. The network architecture is based on two separate networks that disentangle the task into a pose estimation and a non-rigid surface deformation step. Extensive qualitative and quantitative evaluations show that our approach outperforms the state of the art in terms of quality and robustness. This work is an extended version of DeepCap where we provide more detailed explanations, comparisons and results as well as applications.
Dataset Details